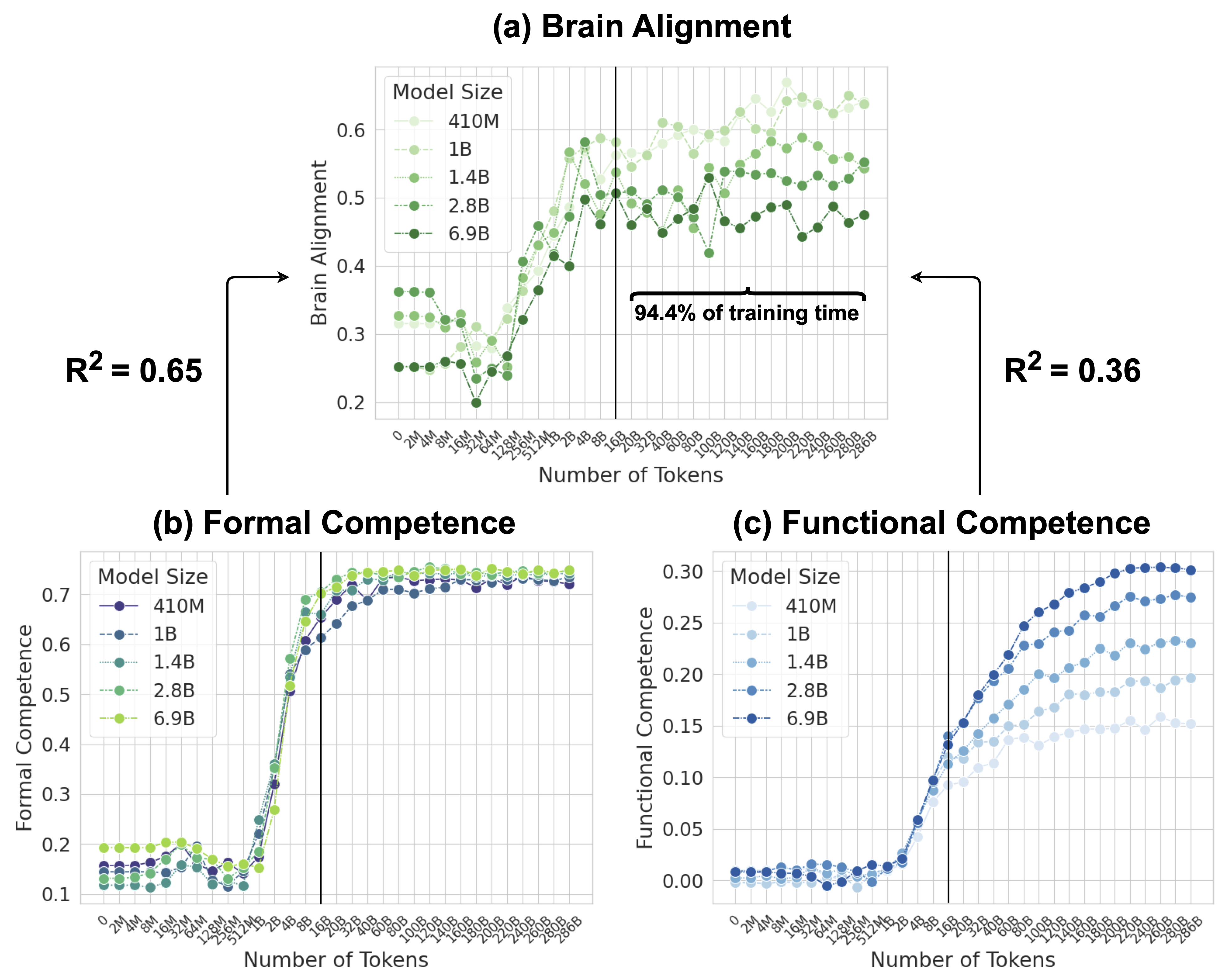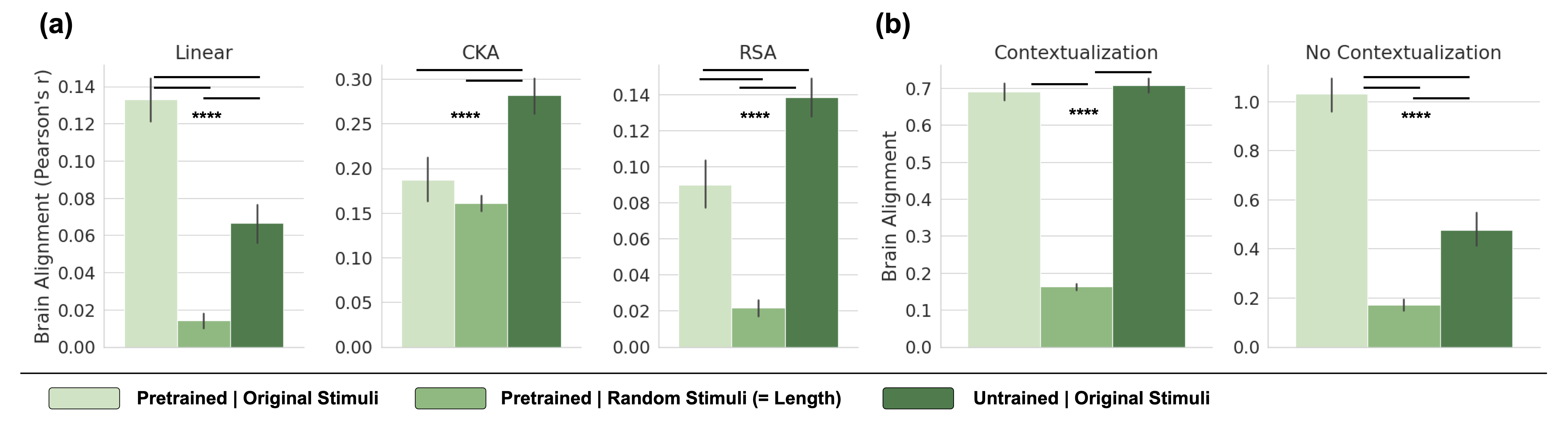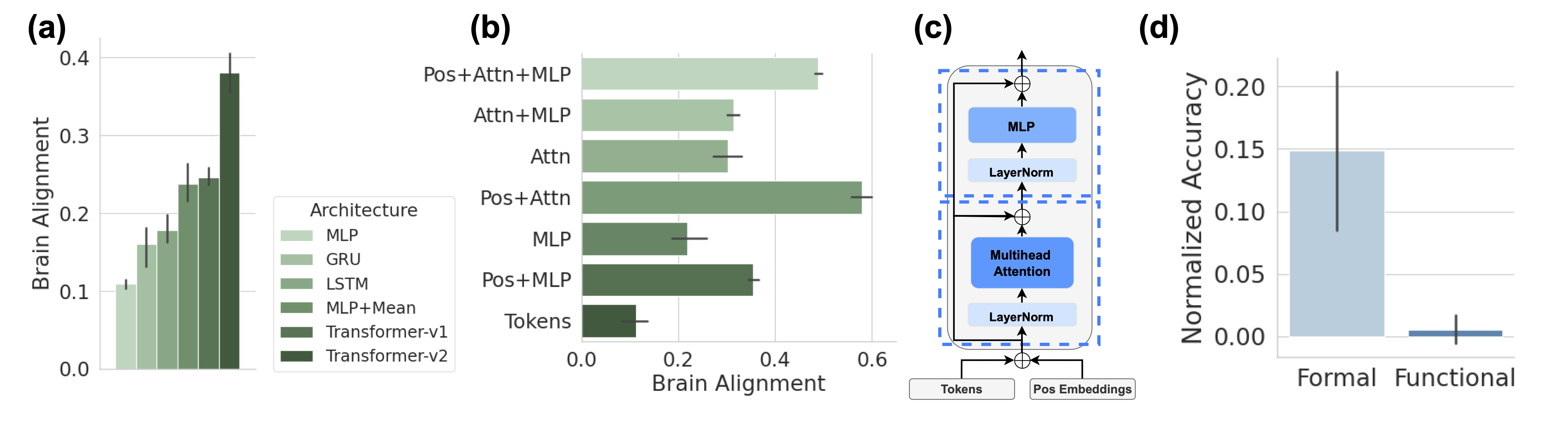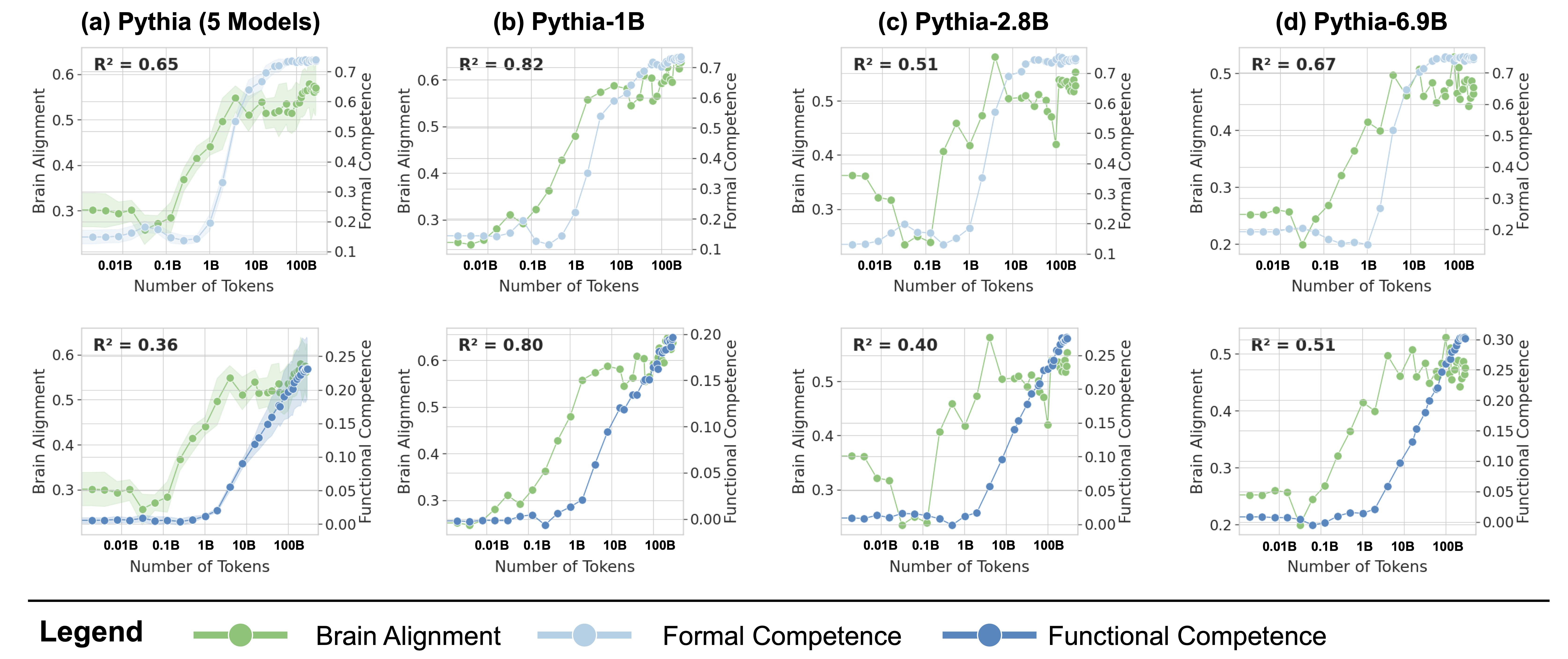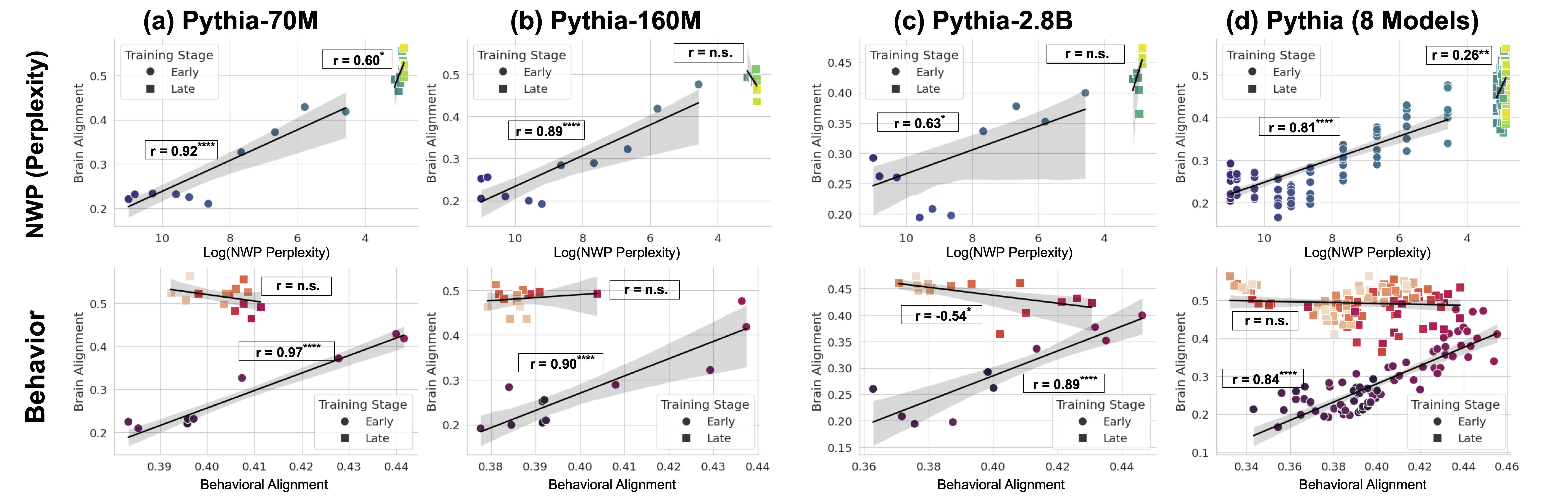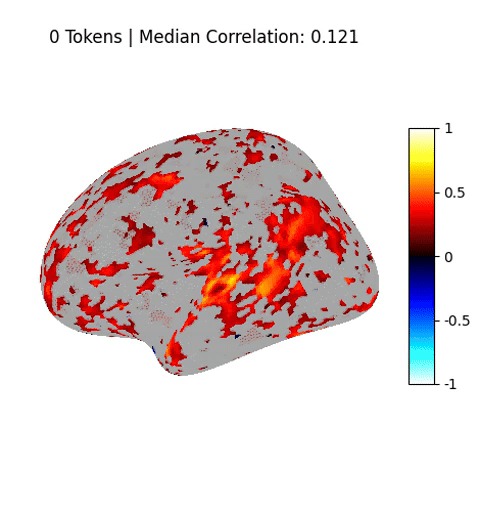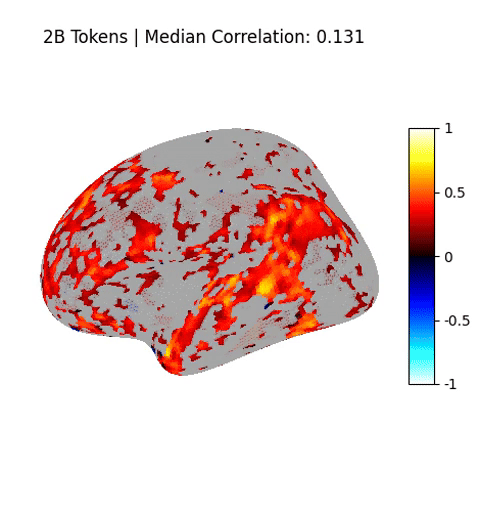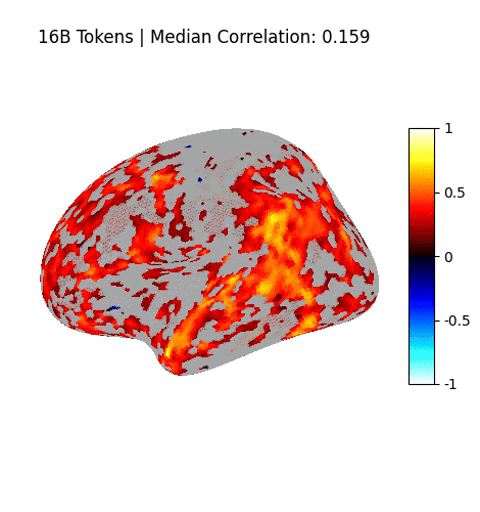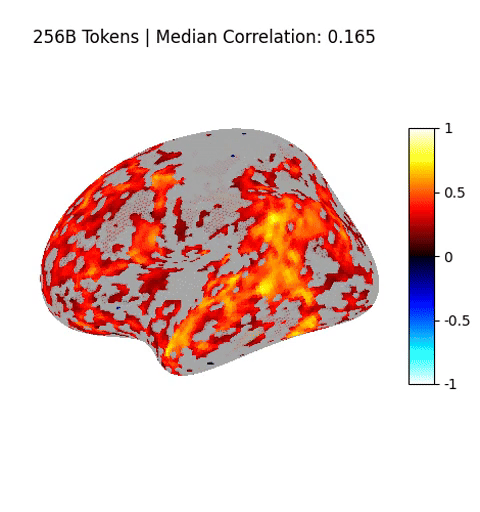
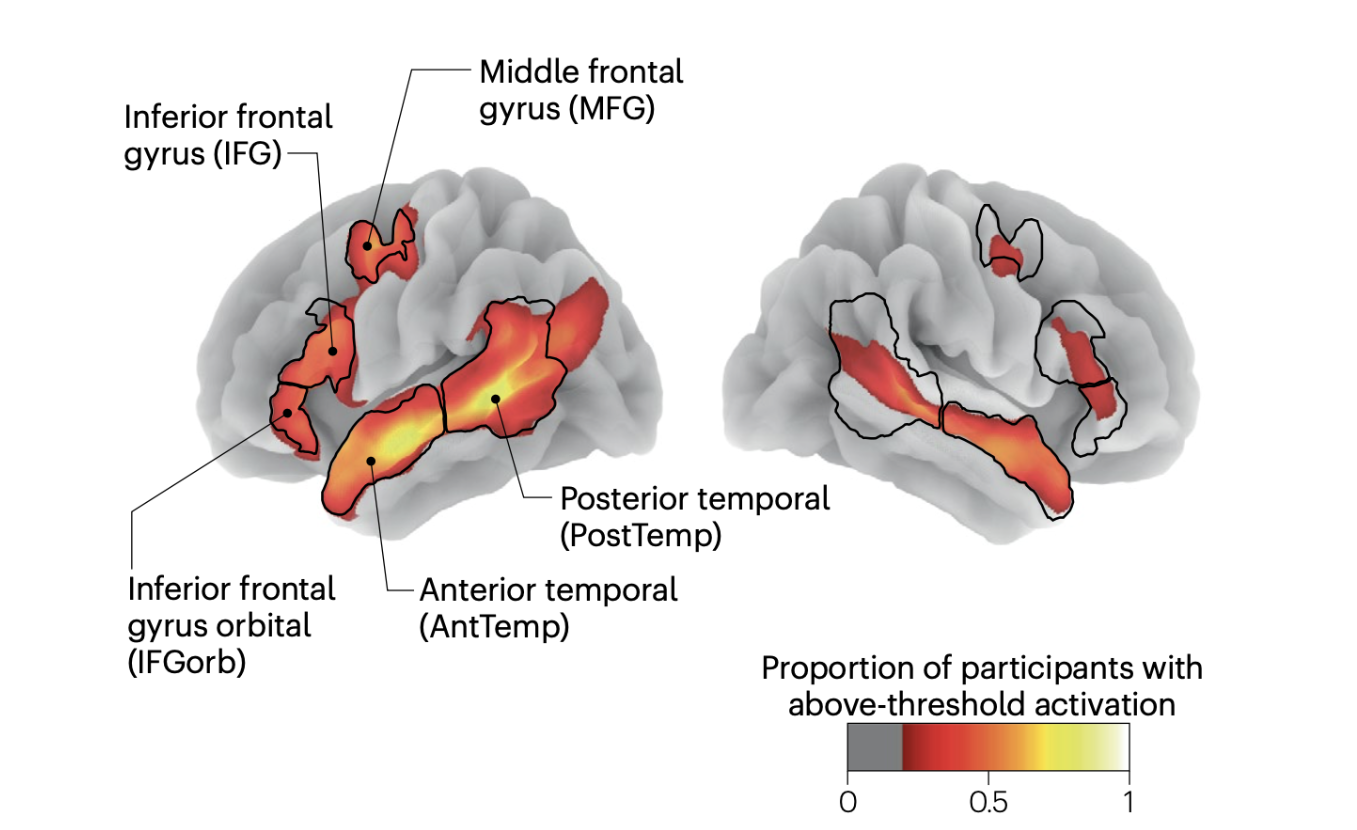
The human language network comprises a set of brain regions that are functionally defined by their increased activity to language inputs over perceptually matched controls (e.g., lists of non-words) (Fedorenko et al., 2010; Lipkin et al., 2022). These regions are predominantly localized in the left hemisphere, within frontal and temporal areas, and demonstrate a strong selectivity for language processing over various non-linguistic tasks such as music perception (Fedorenko et al., 2012;Chen et al., 2023) and arithmetic computation (Fedorenko et al., 2011; Monti et al., 2012). Crucially, these regions exhibit only weak activation in response to meaningless non-word stimuli, whether during comprehension or production (Fedorenko et al., 2010; Hu et al., 2023). This high degree of selectivity is well-established through neuroimaging studies and is further supported by behavioral data from aphasia studies: In individuals with damage confined to these language areas, linguistic abilities are significantly impaired, while other cognitive functions—such as arithmetic computations (Benn et al., 2013; Varley et al., 2005), general reasoning (Varley and Siegal, 2000), and Theory of Mind (Siegal and Varley, 2006)—remain largely intact.
Fedorenko, E., Ivanova, A.A. & Regev, T.I. The language network as a natural kind within the broader landscape of the human brain. Nat. Rev. Neurosci. 25, 289–312 (2024).